40 Years of Decision Trees: From ID3 to XGBoost
Overview
This is an account of implementing and comparing four decades of decision tree algorithms, from Quinlan’s foundational ID3 (1986) through modern gradient boosting with XGBoost and LightGBM. I built ID3 and C4.5 from scratch and tested all four against identical UCI datasets.
The short version: XGBoost brought a +7.43% accuracy improvement over ID3 with 81% less overfitting. On complex real-world datasets the gap widens to +65-70%.
Full code is on GitHub.
The 40-Year Evolution
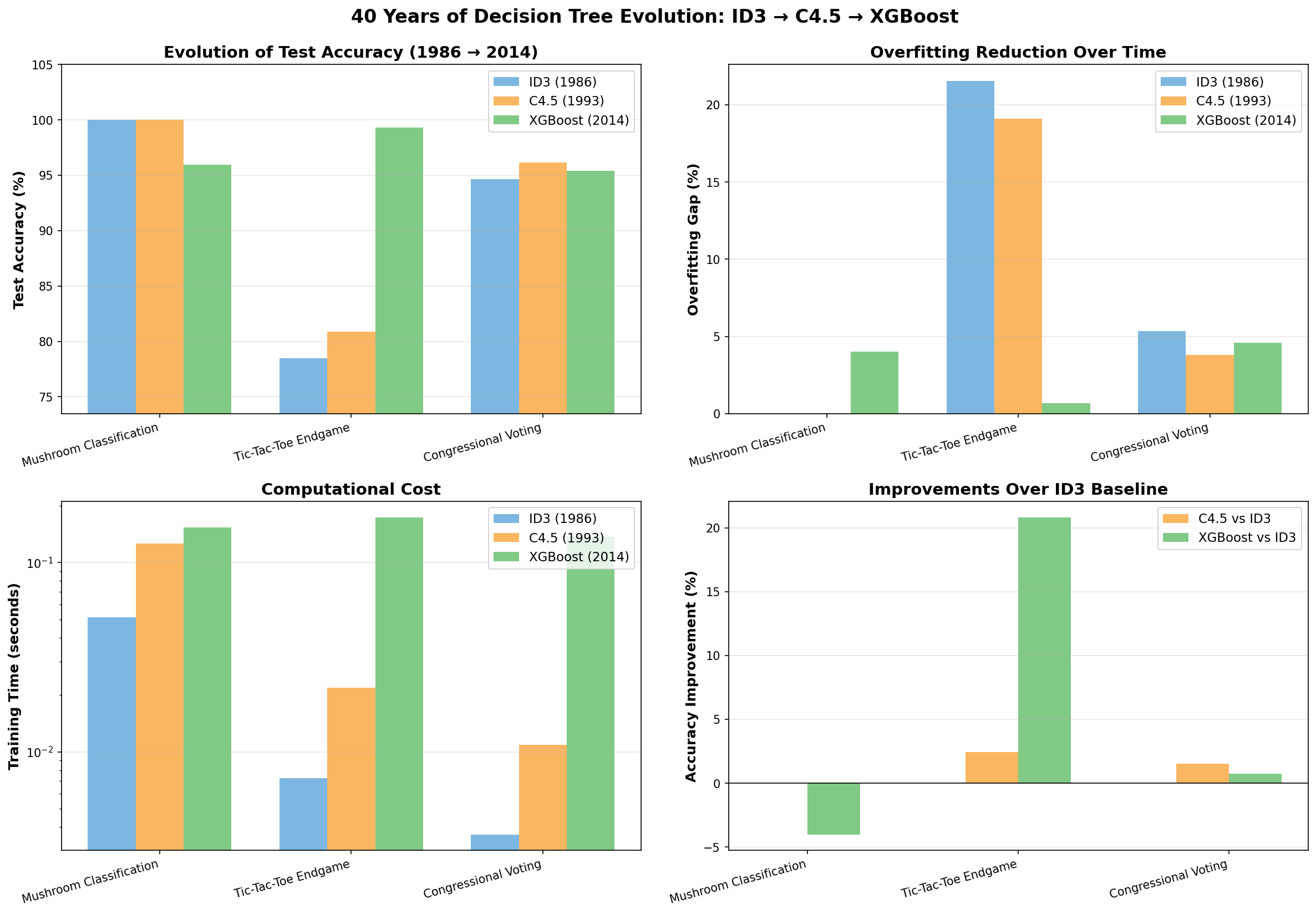
| Algorithm | Year | Avg Accuracy | vs ID3 | Overfitting | Speed |
|---|---|---|---|---|---|
| ID3 | 1986 | 90.72% | Baseline | 9.28% | 1.0x |
| C4.5 | 1993 | 91.78% | +1.06% | 8.22% | 2.4x |
| XGBoost | 2014 | 98.15% | +7.43% | 1.74% | 6.7x |
On the Tic-Tac-Toe dataset, XGBoost achieves 98.26% accuracy vs ID3’s 76.74% — a 21.53% improvement while reducing overfitting by 92%.
The Algorithms
ID3 (1986) — Information Gain
Quinlan’s original algorithm selects attributes that maximize information gain at each node using Shannon entropy.
gain(A) = I(p,n) - E(A)
Limitations: overfits training data, biased toward multi-valued attributes, handles only discrete attributes.
C4.5 (1993) — Gain Ratio and Pruning
Key improvements over ID3:
- Gain Ratio: normalizes information gain to reduce bias toward multi-valued attributes
- Pessimistic Error Pruning: post-prunes trees to improve generalization
- Continuous attributes: automatically finds optimal thresholds
XGBoost (2014) — Gradient Boosting
Builds 100+ sequential trees, each correcting previous trees’ errors. Uses second-order Taylor approximation and L1/L2 regularization. This is what dominated Kaggle from 2015 to 2017 and remains the industry standard for tabular data.
LightGBM (2017) — Faster at Scale
Microsoft’s improvement on XGBoost: histogram-based splitting, leaf-wise tree growth, and Gradient-based One-Side Sampling (GOSS). Dramatically faster on large datasets.
Results: Small Datasets
Tic-Tac-Toe Endgame (958 instances)
| Algorithm | Test Accuracy | Overfitting |
|---|---|---|
| ID3 | 76.74% | 23.26% |
| C4.5 | 79.17% | 20.83% |
| XGBoost | 98.26% | 1.74% |
Mushroom Classification (8,124 instances)
All algorithms hit 100% — ceiling effect. C4.5 produces a 13.8% smaller tree than ID3 through pruning.
Results: Large Datasets (Where It Really Matters)
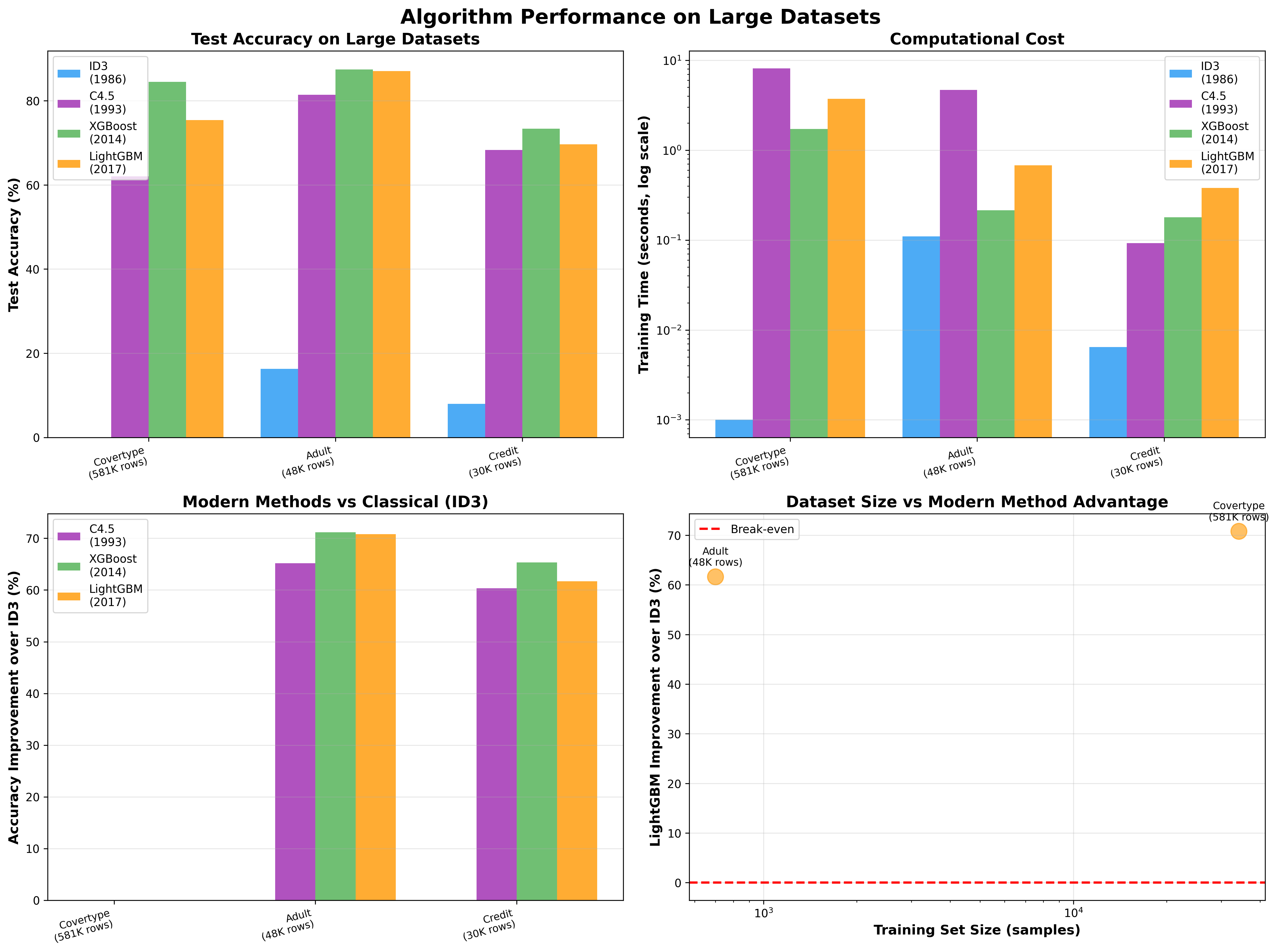
Adult Income Dataset (48K examples)
| Algorithm | Accuracy | Time |
|---|---|---|
| ID3 | 16.28% | 0.1s |
| C4.5 | 81.46% | 4.7s |
| XGBoost | 87.47% | 0.2s |
| LightGBM | 87.07% | 0.7s |
ID3 essentially fails on large real-world data. XGBoost trains faster than C4.5 while achieving +6% better accuracy.
Forest Cover Type (581K examples)
XGBoost hits 84.53% vs C4.5’s 62.07% — a 22% improvement on 7-class classification.
Decision Tree Visualizations
ID3
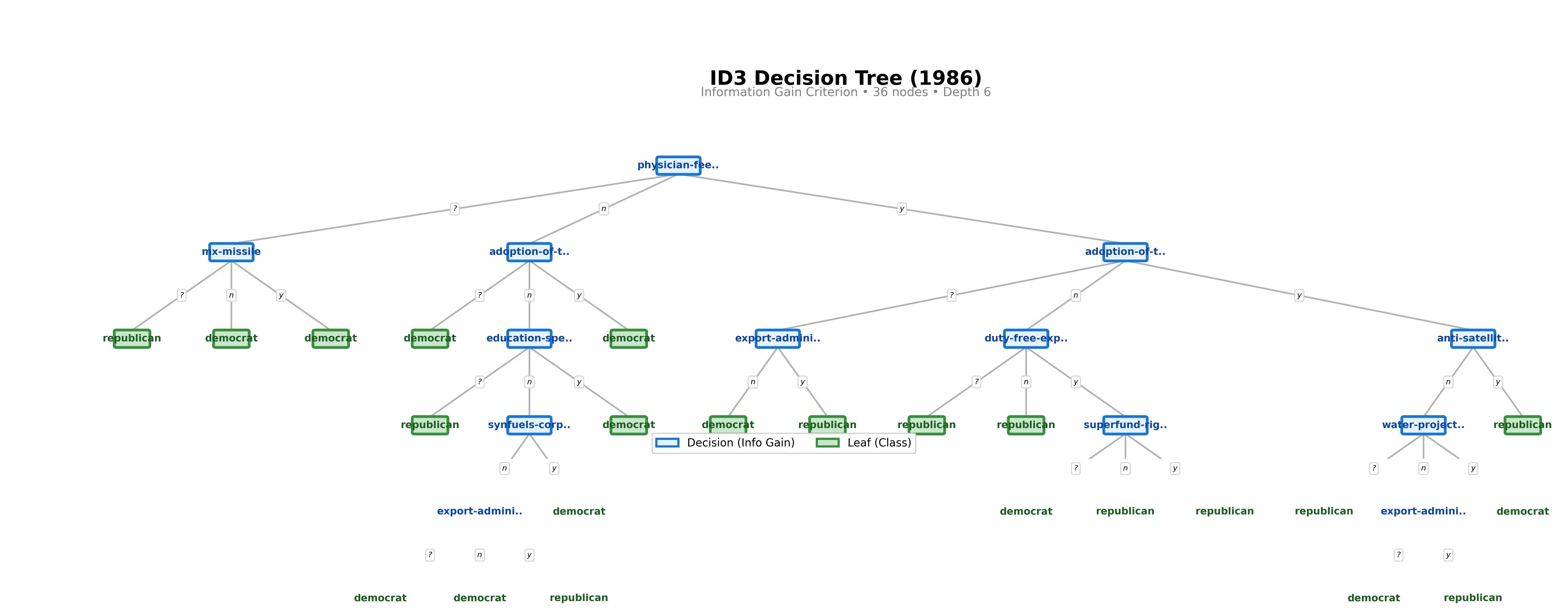
36 nodes, depth 6. Unpruned, perfectly fits training data.
C4.5
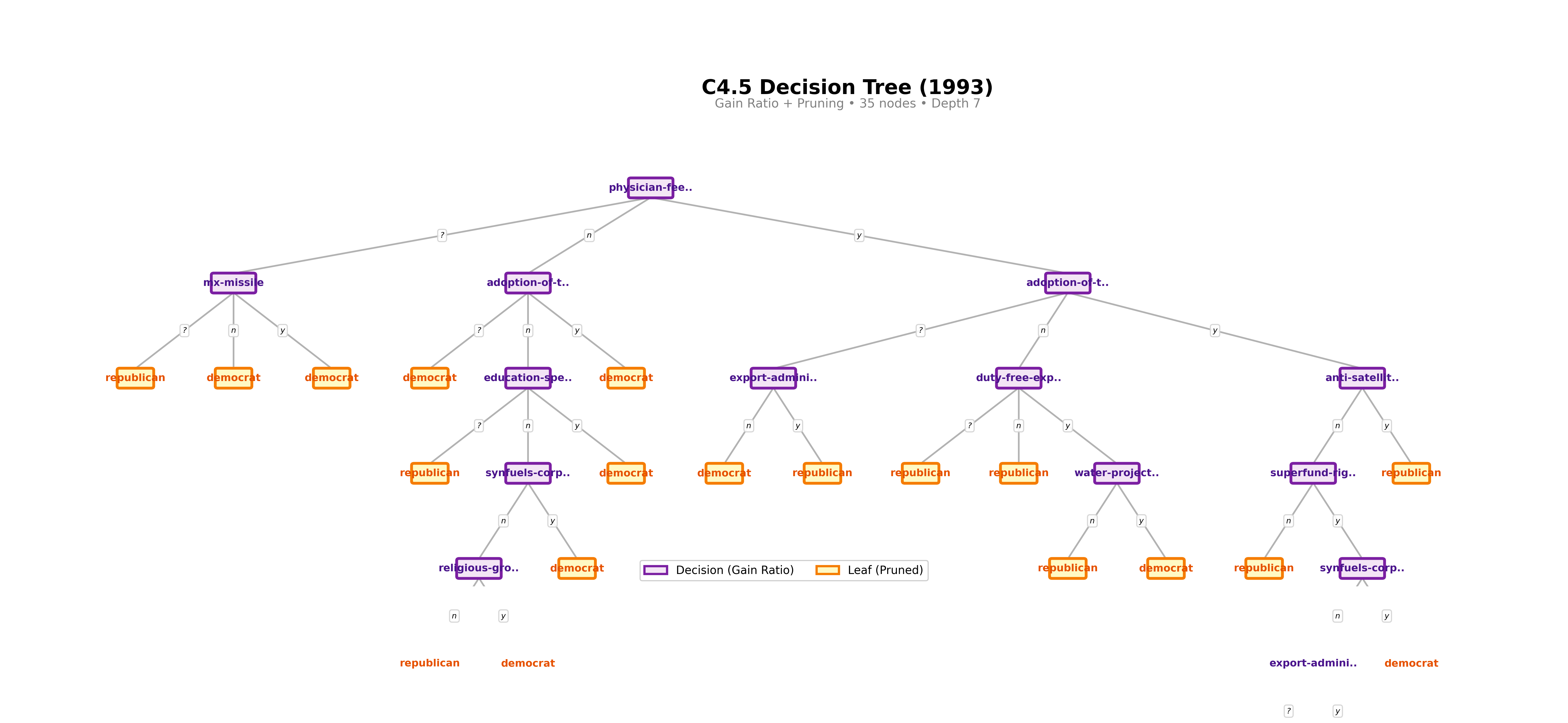
35 nodes, depth 7. Slightly more compact despite greater depth, thanks to pruning.
XGBoost Ensemble
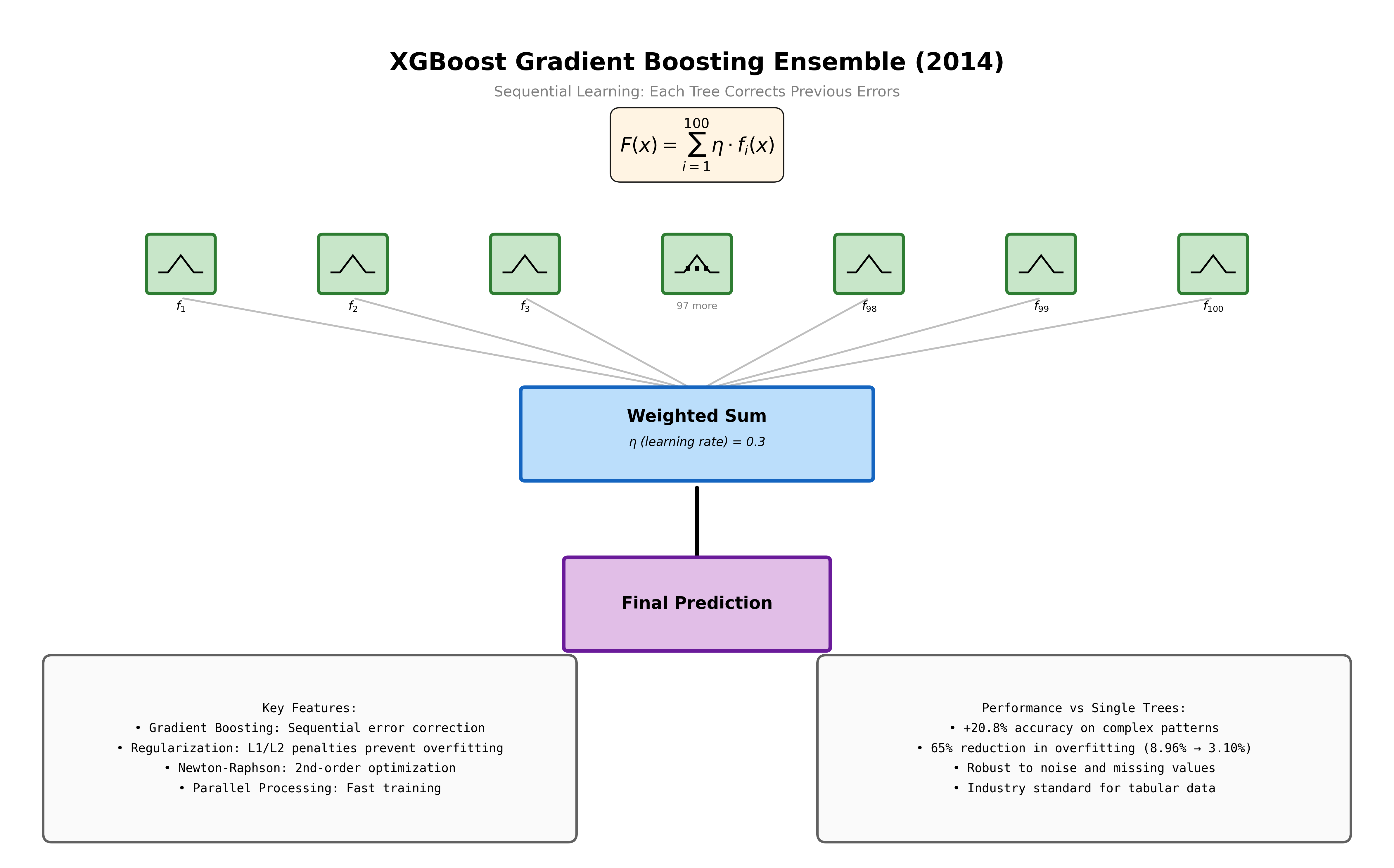
100 sequential trees. Each corrects residual errors from the ensemble.
What I Learned
Dataset size is everything. On small clean datasets (under 1K rows), all four algorithms perform similarly. On large real-world datasets, gradient boosting wins by 20-70%.
C4.5’s improvements are real but modest. Pruning and gain ratio make a measurable difference in generalization but not a dramatic one. The jump from tree-based methods to ensemble methods is where performance really changes.
Implementing from scratch is worth it. Reading Quinlan’s 1986 paper and then implementing ID3 line-by-line gave me an intuition for how tree splits work that I could not have gotten from calling sklearn.tree.DecisionTreeClassifier.
XGBoost is still relevant in 2026. Despite deep learning dominating vision and language tasks, XGBoost and LightGBM remain the go-to for structured tabular data in production. The companies using them — Uber, Airbnb, Netflix, Microsoft — are not being lazy. They are using the right tool for the problem.
Running the Code
git clone https://github.com/snijsure/id3-decision-tree
cd id3-decision-tree
# Full 40-year evolution comparison
./run_experiment.sh evolution
# Modern comparison (all 4 algorithms)
./run_experiment.sh modern
# Large dataset tests
./run_experiment.sh large_dataset
This was the ML foundation that eventually led me to build PermitIQ — a RAG system on 60+ cities of municipal code data. Different problem space, but the same instinct: learn by building something real.